
In a significant move for cloud infrastructure management, AWS has rolled out the next generation of its cloud resilience service. Announced on May 28, 2026, this update introduces a suite of new features, including a hierarchical application model, dependency discovery, and, most notably, generative AI-powered failure mode analysis. The promise is to give platform engineering and site reliability teams a centralized, powerful tool to assess and fortify the resilience of their critical workloads.
Table of Contents
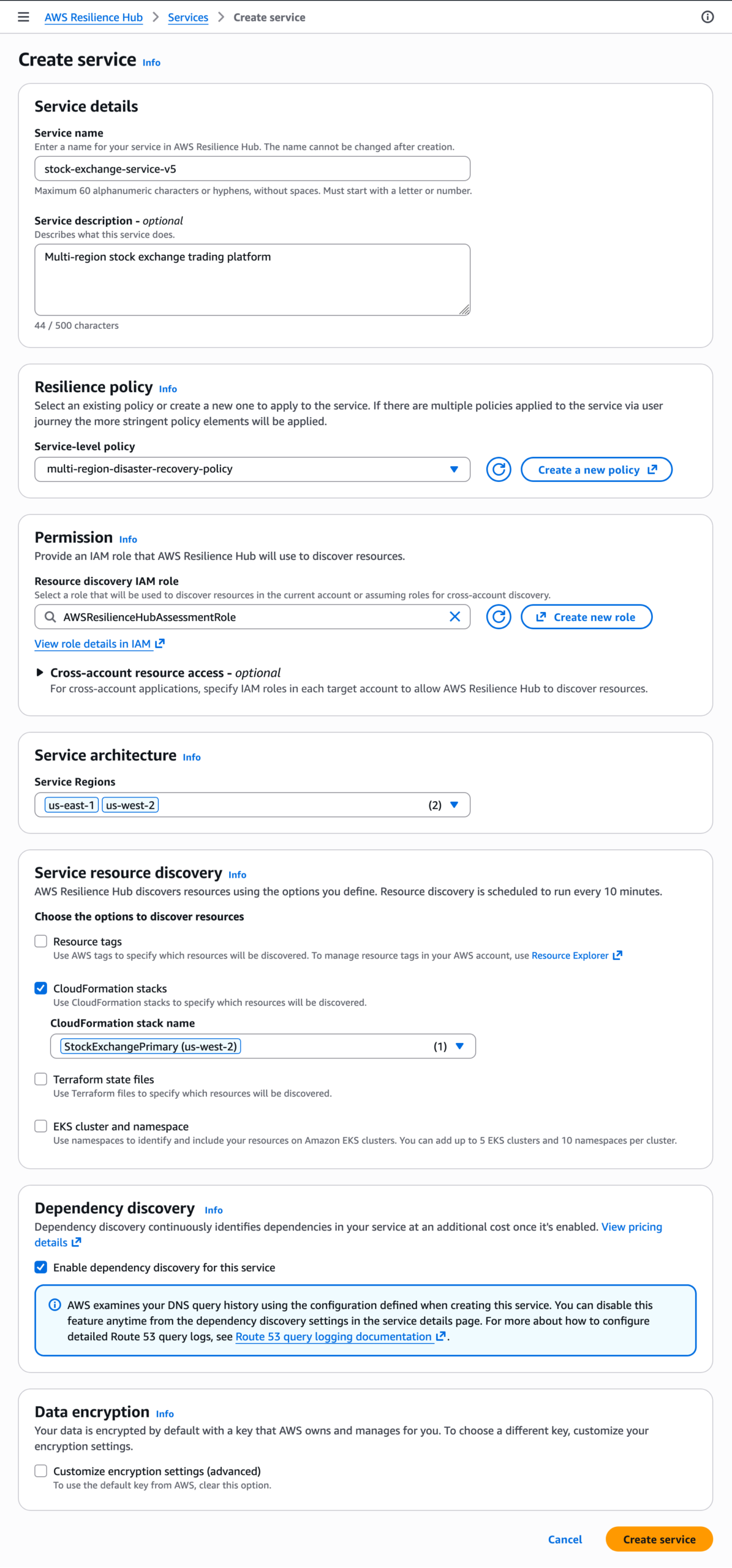
Initially, the pitch is compelling: a single pane of glass to define, measure, and report on resilience across an entire organization. However, this analyst is skeptical. While centralizing resilience goals is a long-overdue step for many enterprises, the injection of generative AI into failure analysis raises pressing questions about accuracy, cost, and the potential for new, unforeseen failure modes. Is this a revolutionary leap forward or a costly gamble on unproven technology for the critical task of keeping systems online?
Mapping the Competitive Landscape for Uptime
To properly assess this move, the context in which the new cloud resilience operates. The cloud resilience market is no longer a niche; it’s a fiercely contested battleground. While AWS has a commanding lead in cloud infrastructure, competitors are not standing still. Solutions like Microsoft’s Azure Chaos Studio and Google Cloud’s chaos engineering tools offer robust alternatives for proactive failure testing. Furthermore, specialized third-party vendors like Arpio and Arctera InfoScale are carving out significant market share by offering targeted, high-availability disaster recovery solutions that promise near-zero downtime.
What sets this apart, supposedly, for the next-gen cloud resilience is its deep integration with the AWS ecosystem and the introduction of generative AI. AWS claims the AI can analyze services against the Well-Architected Framework and the AWS Resilience Analysis Framework to identify potential failure modes and provide actionable recommendations. This creates a powerful, albeit proprietary, moat. The question for enterprise buyers is whether this deep, single-platform integration is a strategic advantage or a fast track to vendor lock-in, making it harder to adopt multi-cloud resilience strategies.
Related article: Ai for legged Faces a Critical Threat From the Sim-to-Real Gap
The real competitive advantage is in its ability to combine infrastructure scanning with AI-driven interpretation. Traditional tools can identify a missing multi-AZ configuration, but the new cloud resilience promises to explain why that matters for a specific business process by modeling critical end-user paths. This business-level understanding is the holy grail for SRE teams struggling to translate technical risks into business impact. However, the effectiveness of this entire model hinges on the quality of the AI’s analysis, a component that remains a black box for now.
Decoding the Hype Around GenAI Failure Analysis
The most ambitious feature of the new cloud resilience is its “generative AI-powered failure mode assessment.” According to the official AWS News Blog post, the AI analyzes your services to identify potential weaknesses and suggest fixes. This sounds revolutionary, but veteran engineers know to be wary of AI-powered silver bullets. The history of IT is littered with “smart” tools that failed to grasp real-world operational complexity.
Our investigation reveals a potential disconnect. While AWS re:Invent sessions from late 2025 discussed using LLMs to hypothesize impairments based on what’s installed on an instance, the actual implementation’s accuracy in complex, multi-account architectures is unproven. An Ippon Blog post from April 2026 correctly identifies that resilience doesn’t live in one account; it spans numerous services and dependencies. The critical question is whether the AI in cloud resilience can truly understand these cross-boundary dependencies or if it will merely optimize locally, giving a false sense of security.
Another point of concern is the AWS Well-Architected Framework and its own Resilience Analysis Framework as the basis for AI assessments. This creates a self-referential loop. The AI is trained on AWS’s definition of “good architecture.” What happens when a novel, non-standard but highly resilient architecture is introduced? Will the AI flag it as non-compliant, forcing teams into a standardized, but potentially less optimal, design? True resilience often requires creative, context-specific solutions that a model trained on general best practices might not recognize or may even penalize.
The Hidden Costs and Regulatory Friction of AI Ops
Beyond the technical questions, the introduction of AI into resilience management creates significant new friction points, particularly around cost and compliance. The pricing model for the new cloud resilience is not yet fully detailed, but integrating AI and running complex assessments is rarely cheap. Will the cost of running frequent AI-powered failure mode analyses outweigh the benefits, especially for smaller organizations? This shift could turn resilience from a practice of good engineering into a line item that budget holders can cut.
Additionally, a significant regulatory hurdle is emerging. As financial and healthcare regulators demand demonstrable proof of operational resilience, the “AI said we were fine” defense will not hold up during an audit after a major outage. An analysis from Ippon highlights that tools like cloud resilience should be treated as a data source, not the ultimate dashboard or governance layer. Organizations, especially in regulated industries, will still need a robust, human-led governance process to validate the AI’s findings and, more importantly, to understand and accept the residual risk.
This exposes a core tension. The service is designed to automate and simplify resilience, but its AI component introduces a layer of abstraction that demands more, not less, human oversight and critical thinking. The recommendations generated by cloud resilience are just that—recommendations. Accepting them without question could lead to a monoculture of resilience strategies, making the entire ecosystem more vulnerable to a single, unforeseen attack vector or failure mode that the AI was not trained to recognize.
Related article: Warehouse automation software Exposes a Hidden Industry Risk
The Bottom Line on cloud resilience
In summary, the next-generation cloud resilience is a bold and ambitious step by AWS to centralize and automate resilience management. The hierarchical application modeling and integration with AWS Organizations are undeniably powerful features that address long-standing challenges in enterprise cloud environments. However, the heavy reliance on a generative AI “black box” for critical failure analysis should give any skeptical tech analyst pause. The tool is likely a powerful asset, but it is not a replacement for deep engineering expertise and a healthy dose of paranoia.
Critical Signals to Watch:
- Monitor: The first independent, third-party audits of the AI’s failure analysis accuracy versus traditional, human-led architectural reviews.
- Watch for: Changes in the pricing structure. Will the AI assessment feature become a premium add-on that prices out smaller customers?
- Key signal: The emergence of “prompt engineering” for resilience policies. How much effort will teams need to expend to guide the AI toward meaningful insights?
- Track: Reports of “AI-induced” failures, where a flawed recommendation was implemented and caused an outage.
- Observe: Competitor responses from Gartner Magic Quadrant leaders and how they counter the integrated AI narrative, either with their own AI or by emphasizing a human-in-the-loop approach.
As of today, the updated cloud resilience represents a significant evolution in cloud-native resilience tooling. It forces the right conversations about RTO/RPO and business impact. But organizations must adopt it with their eyes wide open, treating it as a powerful data source to inform, not dictate, their resilience strategy. The true test will come not in the lab, but during the next major, unexpected cloud outage.